
A Comprehensive Guide to Database Architecture and Design
In today’s data-driven world, the importance of a well-structured and efficient database cannot be overstated. Whether you are a software developer, a data analyst, or a business owner, understanding how to create a good database with a solid architecture is essential for managing and utilizing your data effectively. In this article, we will delve into the key concepts and best practices for designing a database that stands the test of time.
Understanding Database Architecture
Before we dive into the nitty-gritty details of database table design and schema architecture, let’s establish a foundational understanding of database architecture. A database system typically consists of the following components:

- Database Server
- This is the core of your database system, responsible for storing and managing data. Popular database management systems (DBMS) include MySQL, PostgreSQL, Oracle, and Microsoft SQL Server..
- Database
- The database is where your data resides. It comprises one or more tables, each with a specific purpose.
- Table
- Tables are the building blocks of a database. They store structured data in rows and columns, similar to a spreadsheet. Properly designing tables is crucial for efficient data storage and retrieval.
Types of DBMS Architecture
We often categorize systems based on the number of tiers or layers they employ. These classifications provide insights into how applications are structured. Let’s delve into three fundamental database architecture models:
1. One-Tier Architecture (Single-Tier Architecture):
- In the one-tier architecture, also referred to as single-tier, everything operates on a single machine. This approach is commonly used for small-scale applications where both the user interface and database management system reside on the same device. While simple, it may not be suitable for larger or more complex systems due to limitations in scalability and separation of concerns.
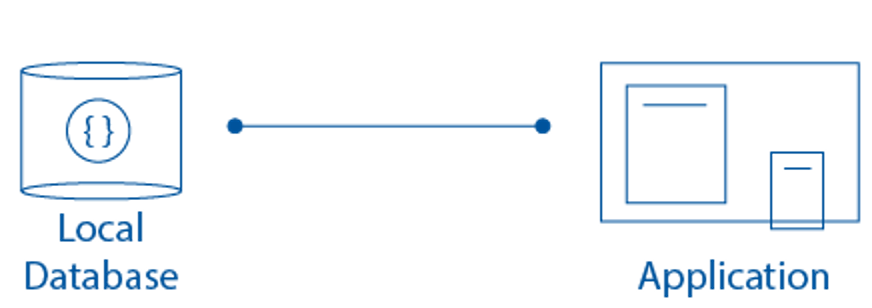
2. Two-Tier Architecture:
- Two-tier architecture, often known as client-server architecture, divides the system into two primary components:
- Client: This handles the user interface and user interactions, forwarding requests to the server.
- Server: The server is responsible for data storage and processing, managing the database and responding to client requests.
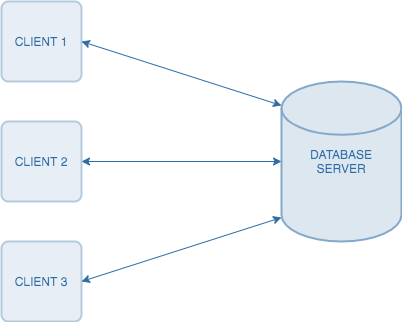
Two-tier architecture offers a separation of the user interface from the database management system, which is advantageous for scalability and maintenance. However, as applications grow in complexity, it can face challenges in scaling efficiently.
3. Three-Tier Architecture:
- Three-tier architecture extends the two-tier model by introducing a middle layer, commonly known as the application or business logic layer, between the client and the server. It comprises three core elements:
- Presentation Tier (Client): This tier manages the user interface and user interactions.
- Application Tier (Middle Tier): It houses the application logic, handling user requests and managing business rules.
- Data Tier (Server): The data tier is responsible for data storage, retrieval, and database operations.
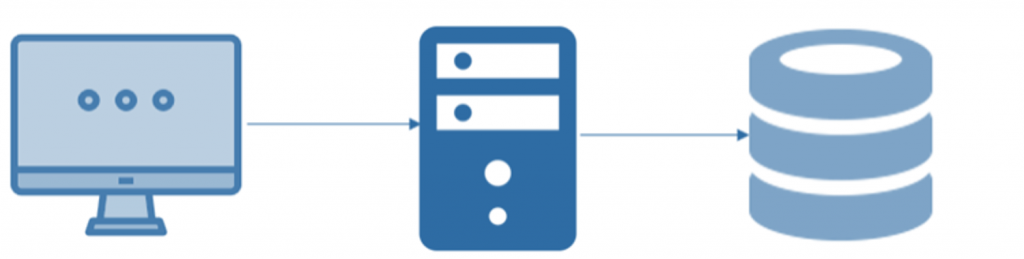
Three-tier architecture offers improved scalability, maintainability, and flexibility compared to the two-tier model. It excels in separating concerns and supports distributed computing, making it a viable choice for larger and more intricate applications.
Database Table Design and Schema Architecture
- Define Clear Goals
- Before you start designing your database, it’s essential to have a clear understanding of your application’s requirements. What type of data will you store? What are the relationships between different data entities? Defining these goals will help shape your database schema.
- Create a Logical Schema
- A logical schema is a high-level representation of your database’s structure. It outlines the tables, their attributes (columns), and the relationships between them. A well-thought-out logical schema simplifies the design process.
- Normalization
- Normalization is a critical concept in database design. It involves breaking down tables into smaller, related tables to eliminate redundancy and improve data integrity. The most common normal forms are 1NF, 2NF, and 3NF.
- Primary Keys (PK)
- A primary key is a unique identifier for each record in a table. It ensures data integrity and facilitates efficient data retrieval. Primary keys can consist of one or more columns and are essential for defining relationships between tables.
- Foreign Keys (FK)
- Foreign keys establish relationships between tables. They are columns in one table that refer to the primary key in another table. Foreign keys maintain data integrity and enable the enforcement of referential integrity constraints.
- Index Keys
- Index keys improve query performance by allowing the database system to quickly locate and retrieve data. They act like the index of a book, making data access faster. Common indexing techniques include B-tree, hash, and bitmap indexes.
- Unique Constraints
- Unique constraints ensure that values in a column (or a set of columns) are unique across all rows, except for NULL values.
- Auto-Increment and Default Values
- Auto-Increment: Automatically generates a unique value for a column, typically used for primary keys.
- Default Values: Assign default values to columns when no value is specified during insertion.
- Data Types
- Select appropriate data types for your columns to minimize storage space and improve query performance. Common data types include integers, strings, dates, and booleans.
- Composite Key
- A composite key is a primary key composed of multiple columns. It is used when a single column cannot uniquely identify rows in a table.
- Clustered and Non-Clustered Indexes
- Clustered Index: In some database systems like SQL Server, the clustered index determines the physical order of data rows in a table. Each table can have only one clustered index.
- Non-Clustered Index: Non-clustered indexes are additional indexes that improve query performance by providing a logical order of data rows. A table can have multiple non-clustered indexes.
- Check Constraint
- A check constraint is used to enforce domain integrity by limiting the values that can be placed in a column. It defines a condition that must be true for each row.
- Identity/Auto-Increment Column
- An identity column (SQL Server) or auto-increment column (e.g., in MySQL) is a column that automatically generates unique values when new rows are inserted.
- Full-Text Search
- Full-text search enables the efficient searching of text within large text fields, such as articles or documents, by creating a searchable index.
- Stored Procedure
- A stored procedure is a precompiled collection of one or more SQL statements that can be executed as a single unit. They are often used for code reusability and security.
- View
- A view is a virtual table created by a query. It allows you to simplify complex queries and present data from one or more tables as if it were a single table.
- Triggers
- A trigger is a set of actions that are automatically executed when a specified event (e.g., INSERT, UPDATE, DELETE) occurs in a database.
- ACID Properties
- ACID (Atomicity, Consistency, Isolation, Durability) properties ensure that database transactions are processed reliably. Transactions must be atomic (indivisible), consistent (adhere to rules), isolated (independent), and durable (persist even after a crash).
- NoSQL Databases
- NoSQL databases, like MongoDB and Cassandra, offer alternatives to traditional relational databases and are suitable for handling unstructured or semi-structured data.
- Replication and Sharding
- Replication: Replication involves creating and maintaining duplicate copies of a database to ensure high availability and data redundancy.
- Sharding: Sharding is a technique for horizontally partitioning data across multiple servers or databases to improve scalability.
- Scaling Out
- Increasing capacity and performance by adding more servers or nodes. Data is distributed across these servers, and incoming requests are balanced for even workloads. It offers high scalability, fault tolerance, cost-efficiency.
- Fault Tolerance
- Fault tolerance in databases is their ability to continue functioning without interruption even when components fail. This is achieved through backup components that automatically replace failed ones, ensuring no service loss. In databases, this is often accomplished through data partitioning and replication, allowing the system to function even if a partition fails. This plays a crucial role in disaster recovery strategies, especially in scenarios involving natural or human-induced disasters.
- Most of the industries that uses this system includes: Financial services, Airports , E-commerce, Aircraft and Space Systems, Train Systems and Nuclear Power Systems.

In summary, a well-structured database is a dynamic tool that can revolutionize your work and decision-making, benefiting businesses and individuals alike. Whether you need stability with Oracle, cost-effectiveness with MariaDB (MySQL), speed with PostgreSQL, or JSON data storage with MongoDB, we recommend the right database for your needs.
As you navigate the complexities of database design and management, remember that these additional terms and concepts, tailored to your specific use case and database system, can enhance your database’s efficiency and effectiveness.
Take the first step in your database journey with Nice Future Inc., your trusted IT Solutions partner. Data is king, and we treat our customers like royalty. Learn more about us at www.nicefutureinc.com and reach out with any questions. Don’t hesitate to ask—we’re here to empower your data-driven success!



 English
English Japanese
Japanese German
German Italian
Italian Portuguese
Portuguese Russian
Russian Spanish
Spanish Turkish
Turkish